9 Getting started with the MESS model
9.1 Key questions
- How do I set up and run a MESS simulation?
- What are the inputs and outputs of MESS?
- What happens when a MESS model runs?
- How do I view and interpret the results of a MESS simulation?
9.2 Lesson objectives
After this lesson, learners should be able to…
- Describe the basic workflow of running a MESS simulation.
- Create and edit a MESS params file, including setting ranges on parameters.
- Understand the meaning of two key MESS model parameters:
Jandcolrate. - Use the command line to run a basic MESS model.
- Describe and interpret the basic outputs of a MESS model.
9.3 Planned exercises
This is the first part of the full tutorial for the MESS model. In this tutorial we’ll focus on the command line interface (CLI), because this is the simplest way to get started, and it will also more likely be how one would run MESS on an HPC. This is meant as a broad introduction to familiarize users with the general workflow, and some of the parameters and terminology.
- Installation
- Getting started with the MESS CLI
- Creating and editing a new params file
- Run simulations using the edited params file
- Inspect the output of the simulation runs
- Setting prior ranges on parameters
- Hands-on experimentation time
9.3.1 Installing MESS
Because we are using the self-contained and pre-instaled docker image, you do not need to install anything for this workshop, rather installation instructions are included for completeness and future information should you wish to install MESS on your home cluster.
The most current implementation of the MESS model is included in the iBioGen package, which is hosted on the iBioGen github and installable either using conda or the remotes R package. Conda is the preferred method, but really either should work.
For the command line install, first install conda and then:
conda create -n iBioGen python=3.10
conda activate iBioGen
conda install -c conda-forge -c ibiogen ibiogenFor the R install:
> install.packages("remotes")
> library(remotes)
> remotes::install_github('iBioGen/iBioGen')Good question! Think of MESS as the idea or the concept and iBioGen as the implentation. It’s the same relationship between the concept/idea of a car and an actual Honda or Ford, they’re both complicated machines made of tons of small parts that do the same job in slighly different ways.
The underlying implementation of iBioGen is python, but we are also working on an implementation of MESS in R which is called roleR. roleR and iBioGen are both complicated software programs made of tons of small parts that implement the idea of the MESS model in slightly different ways. For the purpose of this workshop, because we are interested in the model and not the implementation, we will prefer to refer to it as MESS, in most cases.
9.3.2 Getting started with the MESS CLI
For this exercise we’ll be using the MESS command line interface (CLI), which just means we’ll run it like a program in a terminal. Lets start by getting our rstudio interface changed a bit to make this part easier. Start by collapsing the ‘source’ pane, and expanding the ‘console’ pane on the left, then choose the ‘terminal’ tab in the console pane.
Each grey cell in this tutorial indicates a command line interaction. Lines starting with $ indicate a command that should be executed in a terminal. All lines in code cells beginning with ## are comments and should not be copied and executed. All other lines should be interpreted as output from the issued commands.
## Example Code Cell.
## e.g. Create an empty file in my home directory called `watdo.txt`
$ touch ~/watdo.txt
## Elements in code cells surrounded by angle brackets (e.g. < > ) are
## variables that need to be replaced by the user
##
## Make a directory for your project. When YOU run this replace everything
## (angle brackets and all) with the information that is applicable to you.
$ mkdir <my_project>
## Print "wat" to the screen
$ echo "wat"
watOk, so now that you’re sitting at a command line, we’re ready to begin. To better understand how to use iBioGen to run a MESS model, let’s take a look at the help argument. We will use some of the iBioGen command line arguments in this tutorial (for example: -n, -p, -s, -c). The complete list of optional arguments and their explanation can be accessed with the -h flag (or --help:
$ iBioGen -h
usage: iBioGen [-h] [-n new] [-p params] [-s sims] [-c cores] [-f] [-v] [-q] [-d]
[--ipcluster [ipcluster]]
options:
-h, --help show this help message and exit
-n new create new file 'params-{new}.txt' in current directory
-p params path to params file simulations: params-{name}.txt
-s sims Generate specified number of simulations
-c cores number of CPU cores to use (Default=0=All)
-f force overwrite of existing data
-v do not print to stderror or stdout.
-q do not print anything ever.
-d print lots more info to iBioGen_log.txt.
--ipcluster [ipcluster]
connect to ipcluster profile
* Example command-line usage:
iBioGen -n data ## create new file called params-data.txt
iBioGen -p params-data.txt ## run iBioGen with settings in params file9.3.3 Creating and editing a new params file
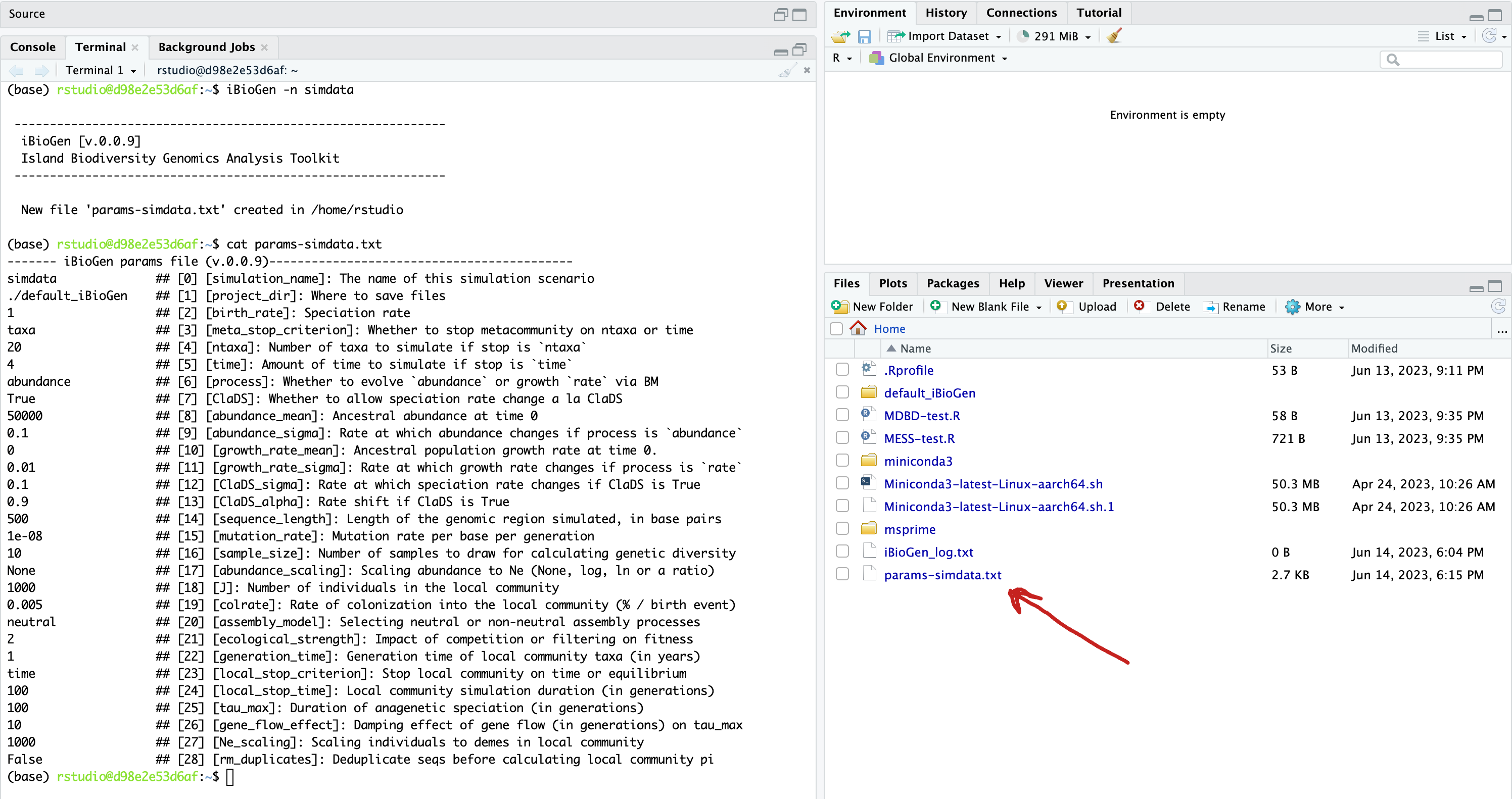
iBioGen uses a text file to hold all the parameters for a given community assembly scenario. Start by creating a new parameters file with the -n flag. This flag requires you to pass in a name for your simulations. In the example we use simdata but the name can be anything at all. Once you start analysing your own data you might call your parameters file something more informative, like the name of your target community and some details on the settings.
## Make a new directory, change directory into it, and then print the working
## directory to make sure you are where you think you are.
$ cd ~
$ mkdir MESS
$ cd MESS
$ pwd
# Create a new params file named 'simdata'
$ iBioGen -n simdata-------------------------------------------------------------
iBioGen [v.0.0.9]
Island Biodiversity Genomics Analysis Toolkit
-------------------------------------------------------------
New file 'params-simdata.txt' created in /home/rstudio/MESSThis will create a file in the current directory called params-simdata.txt. The params file lists on each line one parameter followed by a ## mark, then the name of the parameter, and then a short description of its purpose. Lets take a look at it.
$ cat params-simdata.txt
------- iBioGen params file (v.0.0.9)-------------------------------------------
simdata ## [0] [simulation_name]: The name of this simulation scenario
./default_iBioGen ## [1] [project_dir]: Where to save files
1 ## [2] [birth_rate]: Speciation rate
taxa ## [3] [meta_stop_criterion]: Whether to stop metacommunity on ntaxa or time
20 ## [4] [ntaxa]: Number of taxa to simulate if stop is `ntaxa`
4 ## [5] [time]: Amount of time to simulate if stop is `time`
abundance ## [6] [process]: Whether to evolve `abundance` or growth `rate` via BM
True ## [7] [ClaDS]: Whether to allow speciation rate change a la ClaDS
50000 ## [8] [abundance_mean]: Ancestral abundance at time 0
0.1 ## [9] [abundance_sigma]: Rate at which abundance changes if process is `abundance`
0 ## [10] [growth_rate_mean]: Ancestral population growth rate at time 0.
0.01 ## [11] [growth_rate_sigma]: Rate at which growth rate changes if process is `rate`
0.1 ## [12] [ClaDS_sigma]: Rate at which speciation rate changes if ClaDS is True
0.9 ## [13] [ClaDS_alpha]: Rate shift if ClaDS is True
500 ## [14] [sequence_length]: Length of the genomic region simulated, in base pairs
1e-08 ## [15] [mutation_rate]: Mutation rate per base per generation
10 ## [16] [sample_size]: Number of samples to draw for calculating genetic diversity
None ## [17] [abundance_scaling]: Scaling abundance to Ne (None, log, ln or a ratio)
1000 ## [18] [J]: Number of individuals in the local community
0.005 ## [19] [colrate]: Rate of colonization into the local community (% / birth event)
neutral ## [20] [assembly_model]: Selecting neutral or non-neutral assembly processes
2 ## [21] [ecological_strength]: Impact of competition or filtering on fitness
1 ## [22] [generation_time]: Generation time of local community taxa (in years)
time ## [23] [local_stop_criterion]: Stop local community on time or equilibrium
100 ## [24] [local_stop_time]: Local community simulation duration (in generations)
100 ## [25] [tau_max]: Duration of anagenetic speciation (in generations)
10 ## [26] [gene_flow_effect]: Damping effect of gene flow (in generations) on tau_max
1000 ## [27] [Ne_scaling]: Scaling individuals to demes in local community
False ## [28] [rm_duplicates]: Deduplicate seqs before calculating local community piGreat question! What’s the difference between a CLI argument and a MESS params file parameter, you may be asking yourself? Well, MESS CLI arguments specify how the simulations are performed (e.g. how many to run, how many cores to use, whether to print debugging information, etc), whereas MESS params file parameters dictate the structure of the simulations to run (e.g. sizes of communities, migration rates, specation rates, etc).
The defaults in the params file are all values of moderate size that will generate ‘normal’ looking simulations, and we won’t mess with them for now, but lets just change a couple parameters to get the hang of it. Let’s set J (the # of individuals in the local community)) equal to 500 as this will speed up the simulations (smaller local communities reach equilibrium faster).
We will use the text editor built into Rstudio to modify params-simdata.txt and change this parameter:
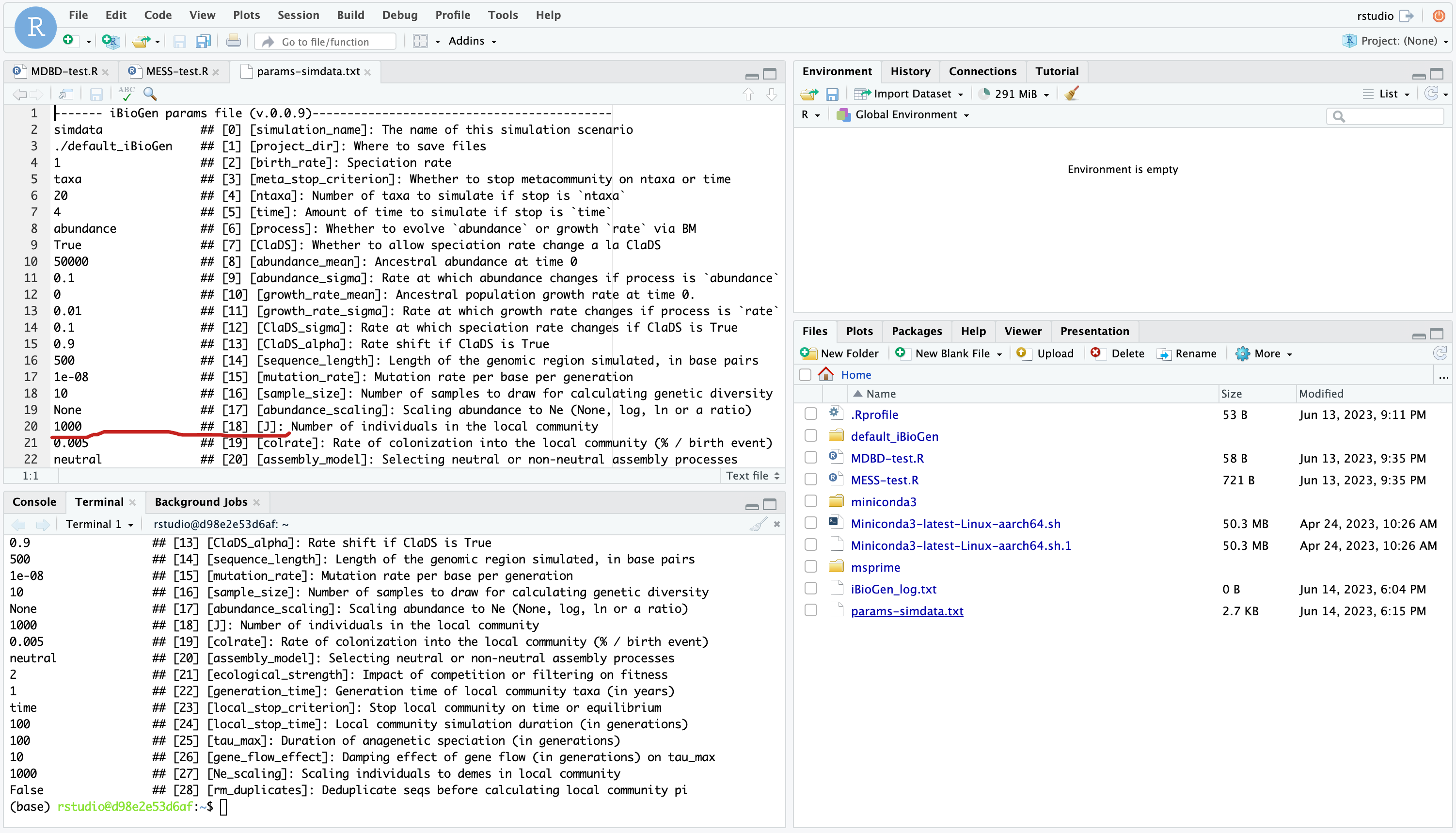
Don’t forget to File->Save after editing your params file! Now you’re ready to run some MESS simulations!
9.3.4 Run simulations using the edited params file
The two most important arguments for the iBioGen command when running simulations are -p which specifies the params file to use, and -s which determines the number of simulations to run.
## Run 10 simulations using our new params file
$ iBioGen -p params-simdata.txt -s 10
-------------------------------------------------------------
iBioGen [v.0.0.9]
Island Biodiversity Genomics Analysis Toolkit
-------------------------------------------------------------
Parallelization disabled.
Generating 10 simulation(s).
[####################] 100% Finished 10 simulations in 0:00:01|This is the simplest possible iBioGen command that will run simulations. It works great for 10 simulations, but typically you’ll need to perform 10 thousand or 10 million simulations, so this approach of generating them one at a time (in serial) is woafully time-consuming. 10x more simulations takes on the order of 10x more wall time:
## Run 100 simulations with our new params file
$ iBioGen -p params-simdata.txt -s 100
-------------------------------------------------------------
iBioGen [v.0.0.9]
Island Biodiversity Genomics Analysis Toolkit
-------------------------------------------------------------
Parallelization disabled.
Generating 100 simulation(s).
[####################] 100% Finished 100 simulations in 0:00:17To facilitate massive parallelization, the iBioGen CLI provides a parallel computing option which will intelligently handle all the parallelization work for you. When invoked with the -c flag, iBioGen portions out simulations among all the cores as they become available.
## Run 100 simulations split across 5 cores
$ iBioGen -p params-simdata.txt -s 100 -c 5
-------------------------------------------------------------
iBioGen [v.0.0.9]
Island Biodiversity Genomics Analysis Toolkit
-------------------------------------------------------------
establishing parallel connection:
host compute node: [5 cores] on d98e2e53d6af
Generating 100 simulation(s).
[####################] 100% Finished 100 simulations in 0:00:05 -c flag is great! Why don’t I put -c 100, it’s going to go so fast!
Ummmm, that’s not really how it works, but I appreciate your enthusiasm. While you very well can use -c 100 and it will definitely do what you say and spin up 100 parallel workers, it will not increase the number of actual cpu cores on your computer. In CLI mode the number of -c cores should never exceed the number of cpu cores on your computer, or else you’ll actually reduce performance, because the parallel workers will all be competing for the (limited) cpu resources.
9.3.5 Inspect the output of the simulation runs
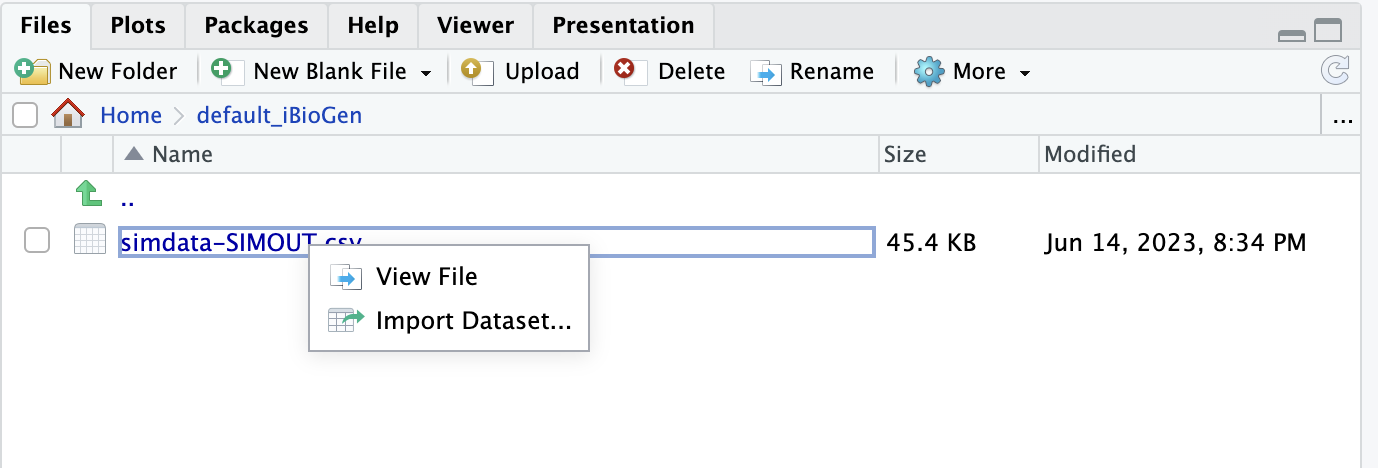
The results from every simulation that you run are written to a file in our project_dir (which defaults to ./default_iBioGen). Lets look in this directory to see what is there:
$ ls ./default_iBioGen
simdata-SIMOUT.csvFirst thing to notice is the strong correlation between the name of the file (simdata-SIMOUT.csv) and the name that we gave when we created the new params file earlier (iBioGen -n simdata). This is not an accident. Output files retain the name of the simulation, and simulation names are enforced to be unique. In this way you can create many new simulations with different parameter values and the output files will not interfere with one another.
Simulation parameters and data are written to this file, one simulation per line. You can calculate the number of lines in this file like this:
$ wc -l ./default_iBioGen/simdata-SIMOUT.csv
210 default_iBioGen/simdata-SIMOUT.csvIt is worth mentioning that running new simulations using the same params file will simply append to this SIMOUT file, it will never destructively remove previously run simulations.
The simulations results are not exactly human readable (they’re not supposed to be), but we can still take a look at them with the linux command head, which is very similar to the same command in R, printing the first few lines of a file to the screen:
## peek at the simulations with head
## -n 2 prints the first 2 lines, the header line and the first simulation
$ head -n 2 default_iBioGen/simdata-SIMOUT.csv
birth_rate meta_stop_criterion ntaxa time process ClaDS abundance_mean abundance_sigma growth_rate_mean growth_rate_sigma ClaDS_sigma ClaDS_alpha sequence_length mutation_rate sample_size abundance_scaling J colrate assembly_model ecological_strength generation_time local_stop_criterion local_stop_time tau_max gene_flow_effect Ne_scaling rm_duplicates meta_obs_ntaxa meta_obs_time local_obs_time(gen) local_obs_time(eq) meta_turnover_rate metadata metatree localdata
1.0 taxa 20 4.0 abundance True 50000 0.1 0.0 0.01 0.1 0.9 500 1e-08 10 None 1000 0.005 neutral 2.0 1.0 time 100.0 100 10 1000 False 20 5.910768727555379 100 0.46399999999999997 0.0 m2-1:22105:0.0019111111111111115:-0.0006829200581811718:1.0702217505635192,m10-1:3476:0.0:0.029954759281765286:0.6636343206049413,m15-1:223:0.0:0.029283014537300305:0.5055426276547345,m15-2:670:0.0:0.03003612090749081:0.5847635679494314,m19-1:3427:0.0011111111111111111:0.03848397068084088:0.7649142929809856,m19-2:1608:0.0:0.038207089121944114:0.7314808093884317,m14-1:2004:0.0:0.04089408370966607:0.5585651686757594,m14-2:1293:0.0:0.040816815424858335:0.6996249403618324,m18-1:330:0.0:0.03415345354321346:0.7065992405115762,m18-2:970:0.0:0.038339667987257256:0.6235489663117895,m17-2:3131:0.0:0.03791778981710612:0.6703418713827751,m12-1:210:0.0:-0.053137235419017756:0.7994138255784535,m12-2:833:0.0:-0.05309037498020786:0.5571929402898937,m8-1:19:0.0:-0.052762281585036805:0.6374722310714049,m8-2:20:0.0:-0.060391958308555684:0.5714480499584342,m6-2:5957:0.0011111111111111111:-0.05508981820070741:0.8656464071932146,m16-1:102:0.0:-0.05673229279720891:0.7255149234973584,m16-2:144:0.0:-0.05360134116045264:0.6314217505682252,m13-2:219:0.0:-0.05079188594847156:0.679215673797093,m9-2:328:0.0:-0.050723924913676346:0.8206959794604726 ((m2-1:3.61047,(((m10-1:0.704907,(m15-1:0.496668,m15-2:0.496668)0:0.208239)0:0.468363,(m19-1:0.115949,m19-2:0.115949)0:1.05732)0:0.220812,((m14-1:0.515387,m14-2:0.515387)0:0.188654,((m18-1:0.324183,m18-2:0.324183)0:0.0355387,m17-2:0.359722)0:0.34432)0:0.69004)0:2.21639)0:2.3002,((((m12-1:0.651564,m12-2:0.651564)0:0.297055,(m8-1:0.937516,m8-2:0.937516)0:0.0111021)0:0.035412,m6-2:0.98403)0:0.930347,(((m16-1:0.382833,m16-2:0.382833)0:0.170452,m13-2:0.553285)0:0.370263,m9-2:0.923547)0:0.990831)0:3.99629); m2-1:0.0:536.0:246.0:-4.403525126405577:99.0:0.010799999999999999,m10-1:12.0:47.0:33.0:2.484183313499446:95.0:0.002,m14-1:15.0:90.0:21.0:3.4839388617026725:89.0:0.0,m17-2:20.0:33.0:27.0:3.8582368853264155:99.0:0.002,m14-2:29.0:57.0:9.0:3.6464075580381112:86.0:0.007666666666666666,m12-2:41.0:77.0:3.0:-2.842822977344748:65.0:0.002,m19-1:43.0:73.0:22.0:2.8828861745086267:97.0:0.003,m19-2:62.0:15.0:10.0:2.737427008766087:86.0:0.0,m6-2:69.0:71.0:22.0:-4.072370312960245:97.0:0.002,m15-1:97.0:1.0:0.0:4.3143827502503225:97.0:0.0The output here is clipped to show the complete results of one simulation. We can alternatively import the simulated data into R as a dataset, which will allow us to view it in a nicer way. Start by browsing to default_iBioGen in the files pane, then click simdata-SIMOUT.csv and choose “Import Dataset…”:
When the Import Text Data box opens the only thing you need to change is the Delimiter which you should set to “Whitespace”, then click “Import”:

Finally, your data imported are presented in the source pane in a nice tabular view. Don’t worry about understanding all (or really any) of these parameters yet, these are all the model parameters that control the simulations. The data which are output by the simulations are also in there, but you have to scroll way over to the right, and there isn’t really a good way to present those yet, because it’s still raw output and has to be summarized before it makes much sense (which we will do in the next lesson!).
The dataset in R won’t automatically reload, so if you run more simulations and want to see the results here you’ll need to repeat the procedure of importing the simdata-SIMOUT.csv we just outlined here.
It seems kind of strange that all the parameters for all the simulations are identical. Wouldn’t it seem useful to be able to vary the parameters in some way to see how the model behaves under different parameter values? Yes, yes it would….
9.3.6 Setting prior ranges on parameters
Rather than explicitly specifying model parameters in the params file, let’s say you’re interested in actually estimating them from the observed data. We can do this by simulating over a range of values for each parameter of interest, and then using an ML inference procedure to estimate these paramters. Let’s say you would like to estimate the size of the local community (J) and the migration rate into the local community (colrate). Edit your params file again in the source pane and change these parameters to specify ranges:
1000-10000 ## [18] [J]: Number of individuals in the local community
0.001-0.01 ## [19] [colrate]: Rate of colonization into the local community (% / birth event)## Run 10 more simulations using the update params file with parameter ranges
$ iBioGen -p params-simdata.txt -s 10
-------------------------------------------------------------
iBioGen [v.0.0.9]
Island Biodiversity Genomics Analysis Toolkit
-------------------------------------------------------------
Parallelization disabled.
Generating 10 simulation(s).
[####################] 100% Finished 10 simulations in 0:00:03|Let’s use the linux command cut to look at just the columns we’re interested in (J and colrate), which are the 17th and 18th columns.
# -d " " indicates the _delimiter_ to use to split columns, a single space
$ cut -f 17,18 -d " " default_iBioGen/simdata-SIMOUT.csv
J colrate
500 0.005
500 0.005
500 0.005
500 0.005
500 0.005
500 0.005
500 0.005
500 0.005
500 0.005
500 0.005
1136 0.0012704714138716813
2186 0.001345609936500913
5897 0.0022431878203297132
6243 0.006219848385382574
1728 0.0013945959644766637
1178 0.008246283294922729
1009 0.0018079819887270672
5229 0.006327492952445476And you’ll see that these parameter values are now taking a range, as we specified. In Part II of this tutorial you will see how we can combine massive amounts of simulations under varying parameter ranges with machine learning to estimate parameters of the model with real data.
9.3.7 Hands-on experimentation: Exploring MESS model behavior with the CLI
Spend the remaining time looking at the params file, and practicing changing parameters and running simulations. See if you can set parameter values that get the model to break! This can be an informative way to understand how models work! This is an open work session, so if you discover an interesting behavior please discuss with the group.
9.4 Key points
- MESS is a conceptual model for unifying biodiversity processes and predicting multidimensional biodiversity patterns. iBioGen and roleR are specific implementations of this conceptual model.
- The
iBioGenCLI offers a simple and efficient way to simulate MESS models. - In
iBioGen, MESS model parameters are contained in a “params” file, and simulation results are written to a “SIMOUT” file. - Placing prior ranges on parameters allows to explore model behavior while varying numerous parameters independently.